Quote
Hmm, how would you then reset $alerthasbeenraised back to false once set true? If it's once the alert has cleared, then that is how the system works now. If you never reset it, the same alert will never occur again, even if if the same problem occurs months later. If it's after the alert has cleared in the system for x number of checks, then you just re-implemented Alert Clear Interval. :)/emoticons/smile@2x.png 2x" style="border:0px;vertical-align:middle;" title=":)" width="20">
I'm glad you asked! It would be set back to false when we mark it as resolved either in Connectwise Manage or in LM, a feature that doesn't currently exist. This way, the alerts generated by flapping would be ingested into the same ticket as updates, but wouldn't change the status of the ticket.
Quote
If you're still not sure what I mean, perhaps you can let me know how you think/expect the integration works (with example) so I get a better idea where there might be confusion.
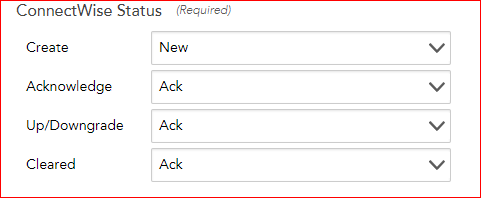
This is the workflow that I'd like to see with LM and Connectwise Manage which N-Central has accomplished with CWM:
Alert threshold for Datapoint A is crossed, alert raised, ticket 001 created, status New.
Alert status clears, ticket 001 is updated, status remains unchanged.
Tech investigates the issue, communicates with the client, makes valuable internal notes, and resolves it. Marks ticket as Solved in CWM. Alert in LM clears because the datapoint cleared, not because the ticket was marked as Solved in CWM.
Days/weeks/months/eons pass.
Alert threshold for Datapoint A is crossed, alert raised, ticket 001 is reopened thereby retaining the earlier communication with the client, the internal notes, etc. Status changes from Solved to New, Ack, Re-opened - not terribly important.
The points are:
-
There should be a one-to-one relationship between an alert raised by a datapoint its ticket; flapping of a datapoint's status should update its ticket, not under any circumstances create a new ticket.
-
A CWM ticket raised by LM should remain open until Solved in CWM.
-
LM should be the truth; the status of an LM alert should not be impacted by the status of its ticket in CWM.
I hope this helps,
Nate